cites
theme: recommendation
theme: recommendation
Deep Neural Networks for YouTube Recommendations
2016
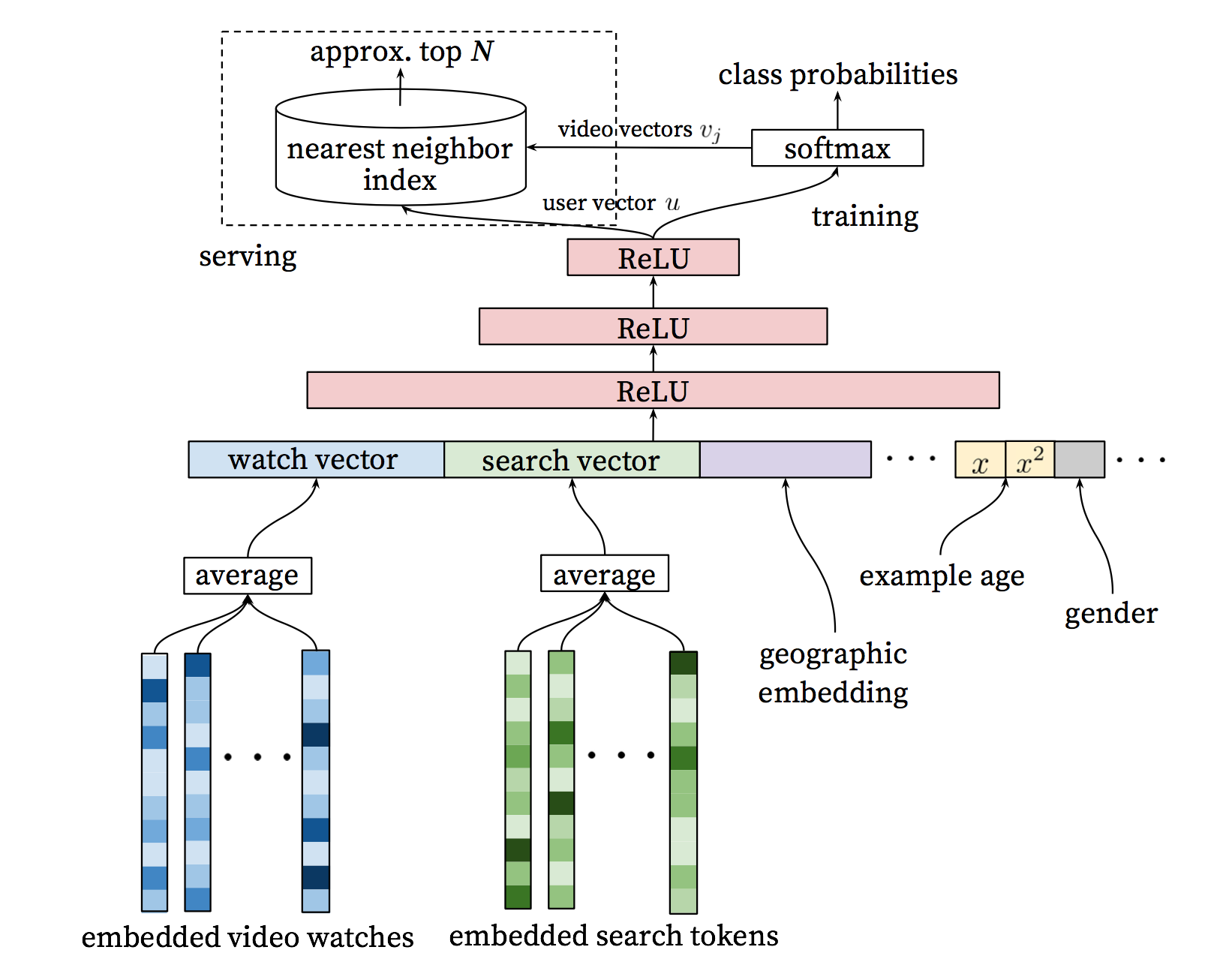
Figure 3: Deep candidate generation model architecture showing embedded sparse features concatenated with dense features. Embeddings are averaged before concatenation to transform variable sized bags of sparse IDs into fixed-width vectors suitable for input to the hidden layers. All hidden layers are fully connected. In training, a cross-entropy loss is minimized with gradient descent on the output of the sampled softmax. At serving, an approximate nearest neighbor lookup is performed to generate hundreds of candidate video recommendations.
(Covington, Adams, & Sargin, 2016)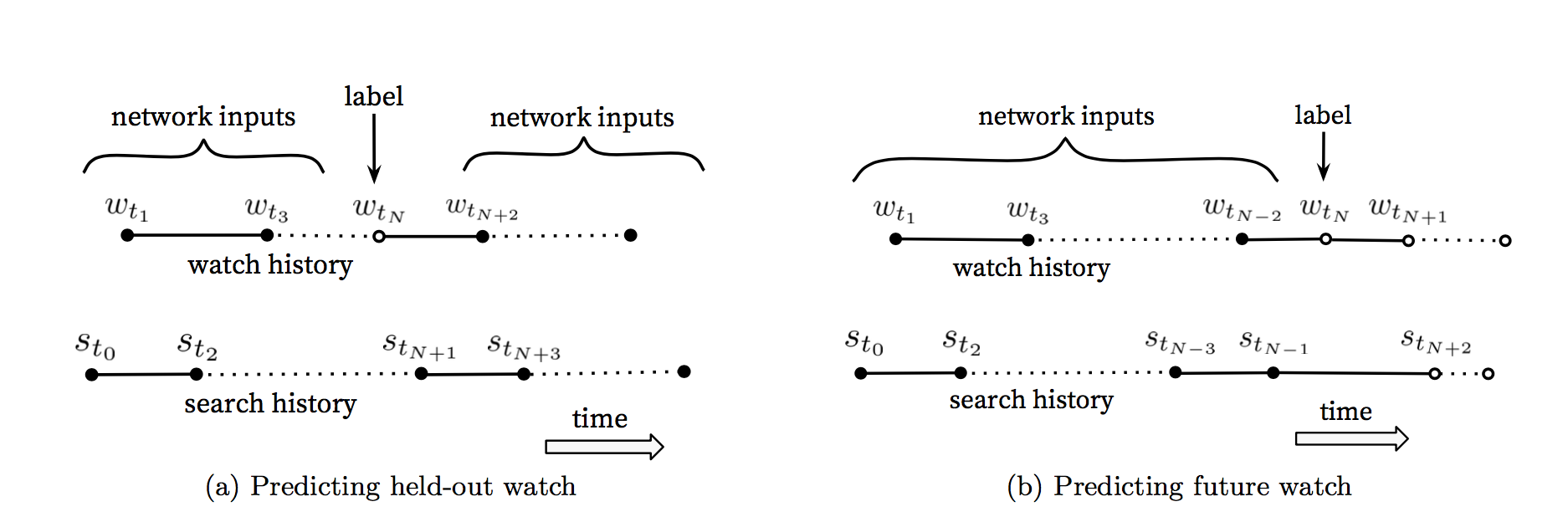
Figure 5: Choosing labels and input context to the model is challenging to evaluate offline but has a large impact on live performance. Here, solid events • are input features to the network while hollow events ◦ are excluded. We found predicting a future watch (5b) performed better in A/B testing. In (5b), the example age is expressed as t~max~ − t~N~ where t~max~ is the maximum observed time in the training data.
(Covington, Adams, & Sargin, 2016)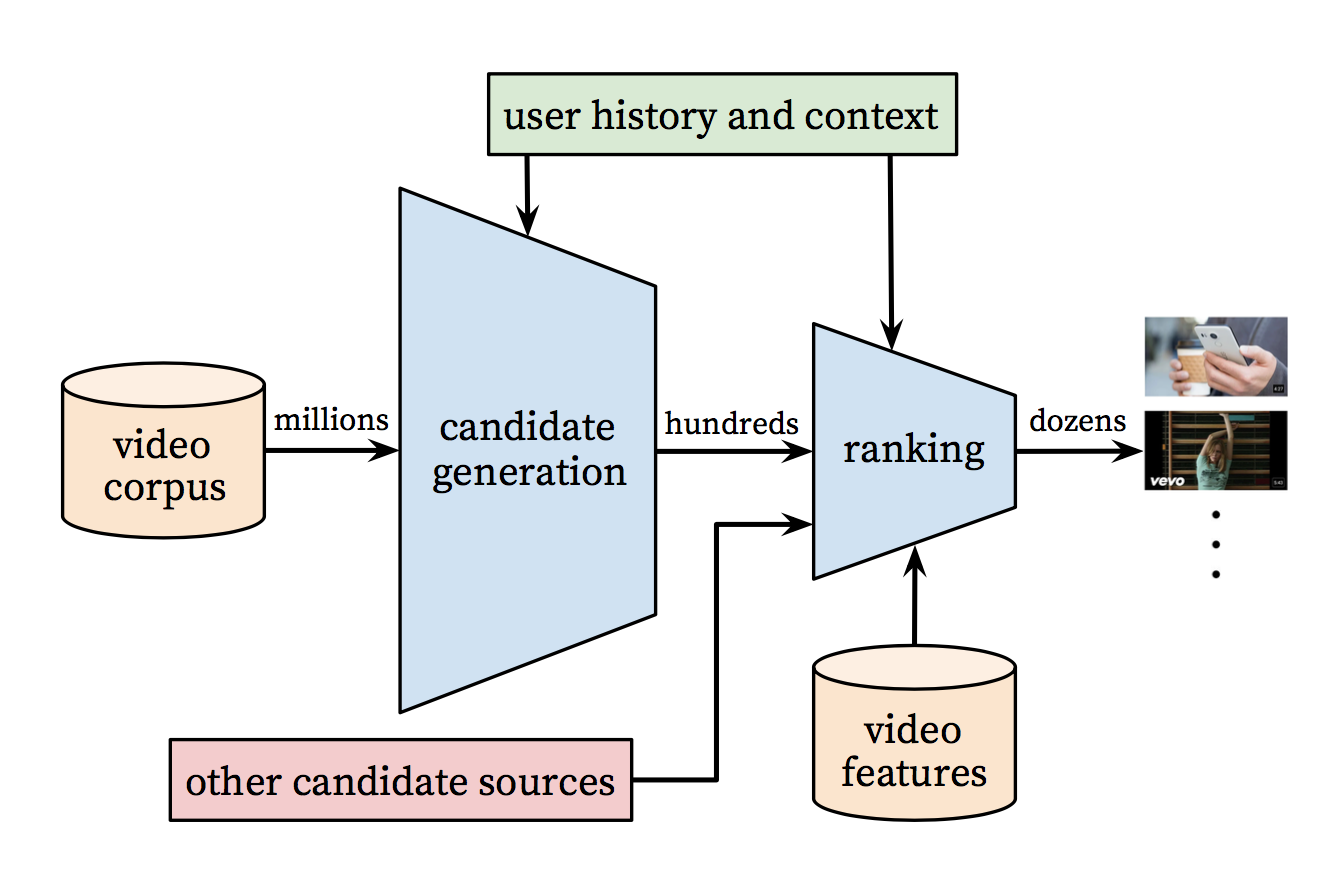
Figure 2: Recommendation system architecture demonstrating the “funnel” where candidate videos are retrieved and ranked before presenting only a few to the user.
(Covington, Adams, & Sargin, 2016)Many hours worth of videos are uploaded each second to YouTube. Recommending this recently uploaded (“fresh”) content is extremely important for YouTube as a product. We consistently observe that users prefer fresh content, though not at the expense of relevance. In addition to the first-order effect of simply recommending new videos that users want to watch, there is a critical secondary phenomenon of boot- strapping and propagating viral content. Machine learning systems often exhibit an implicit bias towards the past because they are trained to predict future behavior from historical examples.
(Covington, Adams, & Sargin, 2016)Covington, P., Adams, J., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems (pp. 191–198). Boston, MA, USA: ACM. [link]
cites
theme: recommendation
theme: recommendation