device_evolution
theme: eugenics
theme: n-dimensional_gaze
theme: n-dimensional_gaze
Iris Dataset
1936
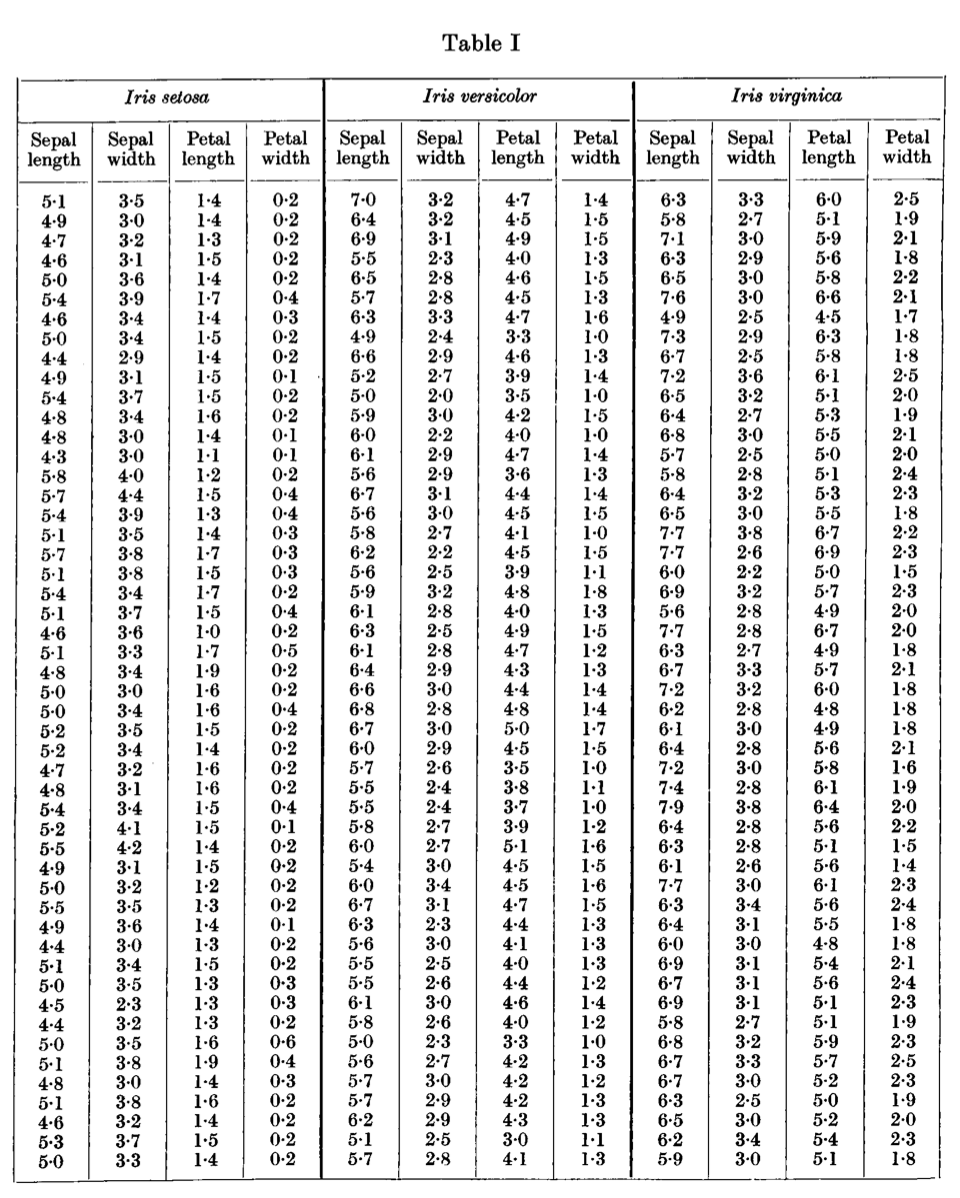
Table I shows measurements of the flowers of fifty plants each of the two species Iris setosa and I. versiwlor, found growing together in the same colony and measured by Dr E. Anderson, to whom I am indebted for the use of the data.
(Fisher, 1936)
Fig. 1. Frequency histograms of the discriminating linear function, for three species of Iris.
(Fisher, 1936)When two or more populations have been measured in several characters, x1, …, x8, special interest attaches to certain linear functions of the measurements by which the populations are best discriminated.
(Fisher, 1936)Anderson’s Iris data, which we think was first published in Fisher, has become a popular set of labeled data for testing—and especially for comparing—clustering algorithms and classifiers. It is, of course, entirely appropriate and in the spirit of scientific inquiry to make and publish comparisons of models and their performance on common data sets and the pattern recognition community has used Iris in perhaps a thousand papers for just this reason— or have we?
During the writing of this book we have discovered (perhaps others have known this for a long time, but we did not) that there are at least two (and, hence, probably half a dozen) different well-publicized versions of Iris.
Bezdek, J. C., Keller, J. M., Krishnapuram, R., Kuncheva, L. I. and Pal, N. R. (1999) ‘Will the real iris data please stand up?’, IEEE Transactions On Fuzzy Systems, 7(3). [link]
Fisher, R. A. (1936) ‘The Use of Multiple Measurements in Taxonomic Problems’, Annals of Eugenics. Blackwell Publishing Ltd, 7(2), pp. 179–188. [link]
device_evolution
theme: eugenics
theme: n-dimensional_gaze
theme: n-dimensional_gaze